The Problem with Traditional Thinking
Most systems are designed with an implicit assumption: > “Things will work as expected.” Failure is treated as:- An edge case
- A rare exception
- Something to handle later
- Work well under ideal conditions
- Break under stress
- Require manual intervention during failure
The Cost of Ignoring Failure
When failure is not part of the design:- Systems enter inconsistent states
- Debugging depends on human interpretation
- Recovery becomes slow and uncertain
- Trust in the system degrades
The VaultLine Shift
VaultLine changes the fundamental question. Instead of asking: > “How do we avoid failure?” It asks: > “How do we remain correct even when failure happens?” This is the foundation of failure-first design.What Failure-First Design Means
Failure-first design treats failure as a design input, not an afterthought. Every part of the system is built with these assumptions:Traditional vs Failure-First Systems
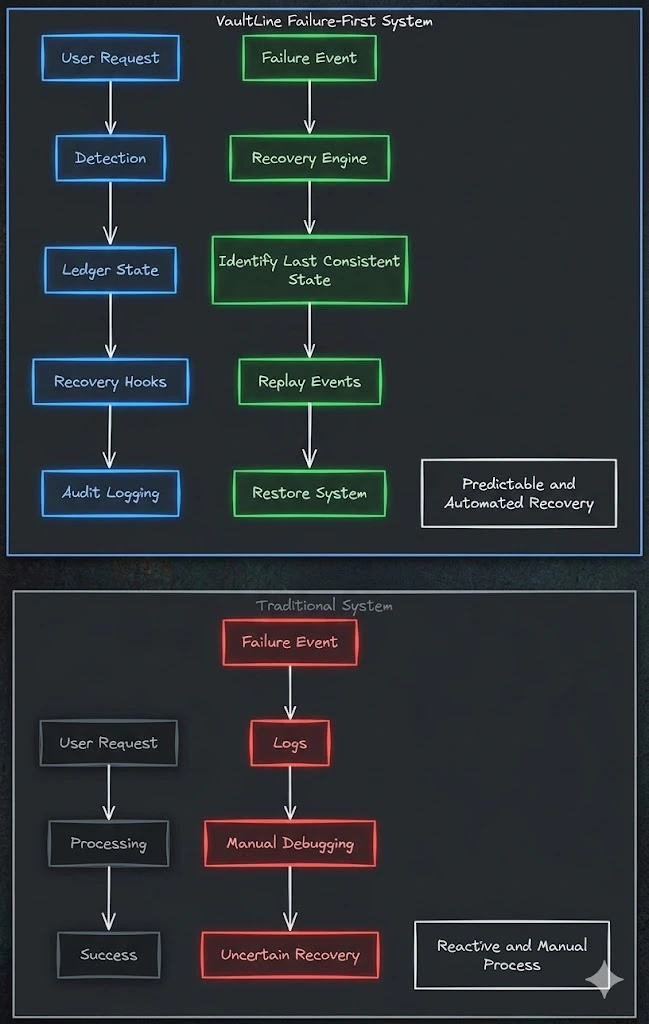
- Failure will happen
- It may happen at any step
- It may happen partially
- It may happen repeatedly
System Behavior Under Failure
In a failure-first system, when something breaks:- The system detects the issue early
- The current state remains consistent
- The failure is contained
- Recovery is triggered automatically
- The system returns to a correct state
Design Principles
1. Assume Failure at Every Step
Every operation is designed with the possibility of failure. Not just total failure — but partial, delayed, or inconsistent execution.2. Make State Observable
The system always knows:- What has happened
- What is happening
- What should happen next
3. Prepare Recovery in Advance
Recovery is not designed during failure. It is built into the system beforehand. Every operation carries:- Context
- Traceability
- Recovery pathways
4. Contain Failure
Failures do not spread uncontrollably. They are isolated so that:- One component failing does not break everything
- The rest of the system remains stable
5. Keep the System Deterministic
Even under failure:- The system behaves predictably
- Outcomes are consistent
- State transitions are controlled
Failure is a State, Not an Event
Traditional systems treat failure as a moment. VaultLine treats failure as a state the system can operate within. This means:- The system continues to function
- Integrity is preserved
- Recovery happens as part of normal operation
What Makes This Different
Most systems aim for:- High availability
- Fast performance
- Correctness under failure
Why it matters
Without failure-first design:- Systems behave unpredictably under stress
- Failures create cascading issues
- Recovery becomes increasingly difficult
- Failures are expected
- Behavior is controlled
- Recovery is predictable
- Systems remain trustworthy