Why Recoverability Matters
Modern systems are distributed, asynchronous, and complex. Failures are not rare events — they are inevitable:- Network interruptions
- Partial service outages
- Data inconsistencies
- Unexpected edge cases
- External dependency failures
The Problem with Traditional Systems
In most architectures, recovery is reactive and unclear:- Logs are inspected after failure
- Engineers manually debug issues
- State inconsistencies are hard to trace
- Recovery paths are undefined or ad-hoc
- ❌ Data corruption or drift
- ❌ Long recovery times
- ❌ Hidden system inconsistencies
- ❌ Compliance and audit failures
VaultLine Approach
VaultLine builds systems where recovery is designed, not improvised. Every action in the system is:- Recorded → nothing is lost
- Traceable → everything can be understood
- Replayable → state can be rebuilt
Core Principles of Recoverability
1. Deterministic Recovery
Recovery is not guesswork. For every failure scenario:- The recovery path is predefined
- The outcome is predictable
- The system behaves consistently
2. Replayable State
The system does not rely on current state alone. Instead:- All events are recorded
- State can be reconstructed from history
- Debugging past failures
- Rebuilding corrupted states
- Verifying system correctness
3. Failure Isolation
Failures are contained within boundaries. Instead of cascading:- A failed component does not break the entire system
- Recovery happens locally where possible
4. Continuous Recovery Readiness
Recovery is not triggered only during failure. The system is always:- Recording events
- Maintaining checkpoints
- Preparing recovery paths
Recovery Flow (Conceptual)
A transaction in VaultLine is never just processed — it is prepared for recovery at every step.\
System-Level Recovery Flow
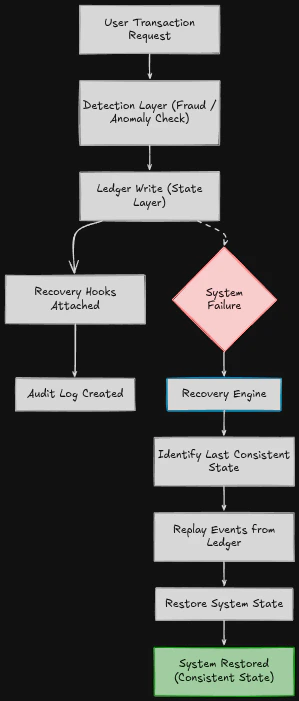
\
- Transaction enters system
- System records the intent
- Detection layer evaluates anomalies
- State update is written to ledger
- Recovery hooks are attached
- Audit trail is stored
- The system identifies the last consistent state
- Replays events if needed
- Restores correctness deterministically
What Makes VaultLine Different
Traditional systems aim for: > High availability VaultLine ensures: > Correctness under failure This is a fundamental shift.Why it matters
Without recoverability:- Systems silently drift into inconsistent states
- Failures compound over time
- Debugging becomes harder
- Trust erodes
- Recovery is fast
- Outcomes are predictable
- State remains consistent
- Systems remain trustworthy